Overview
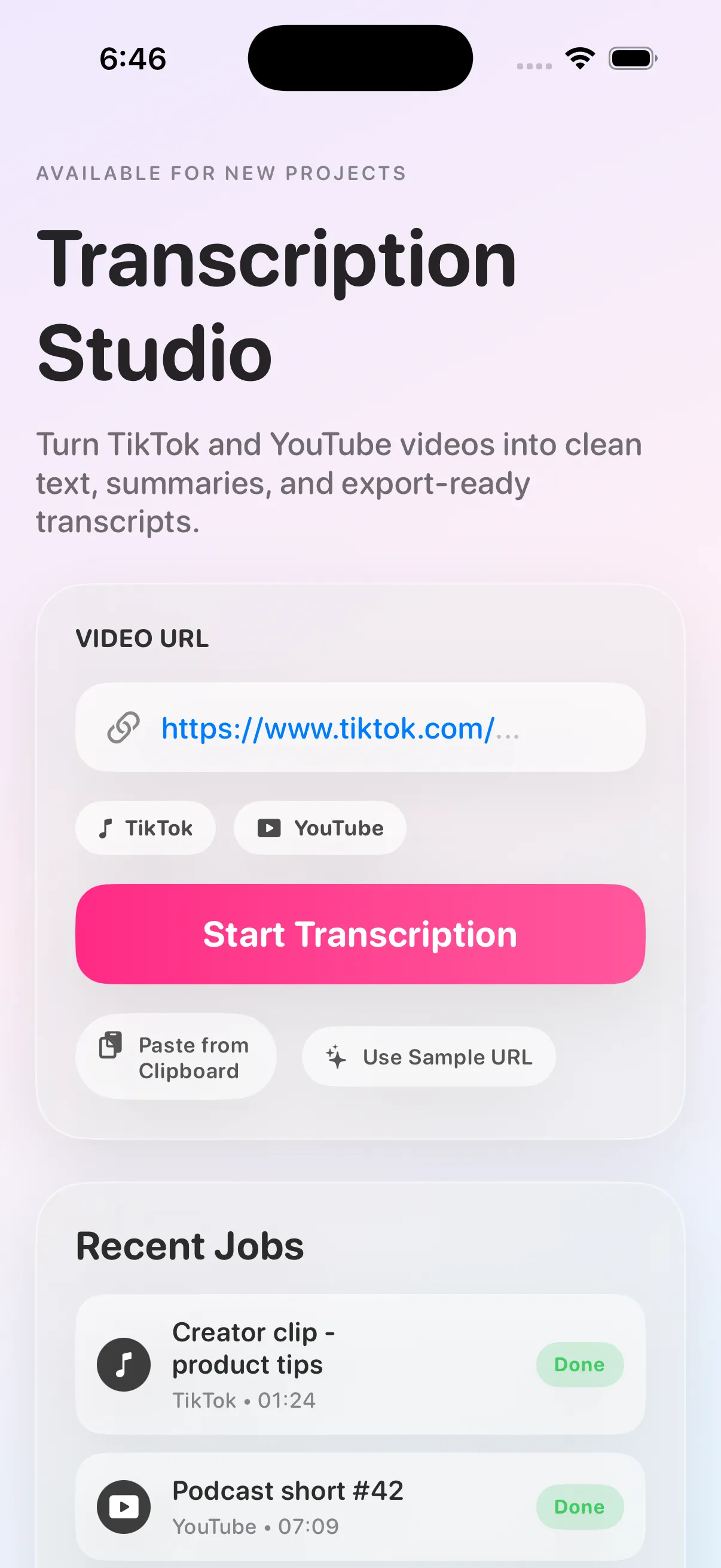
Transcribing App started as a simple idea: make video transcription feel instant and stress-free for people who just need results. Instead of forcing users through technical settings, the product focuses on one clean flow — submit a link, monitor progress, and receive usable text quickly.
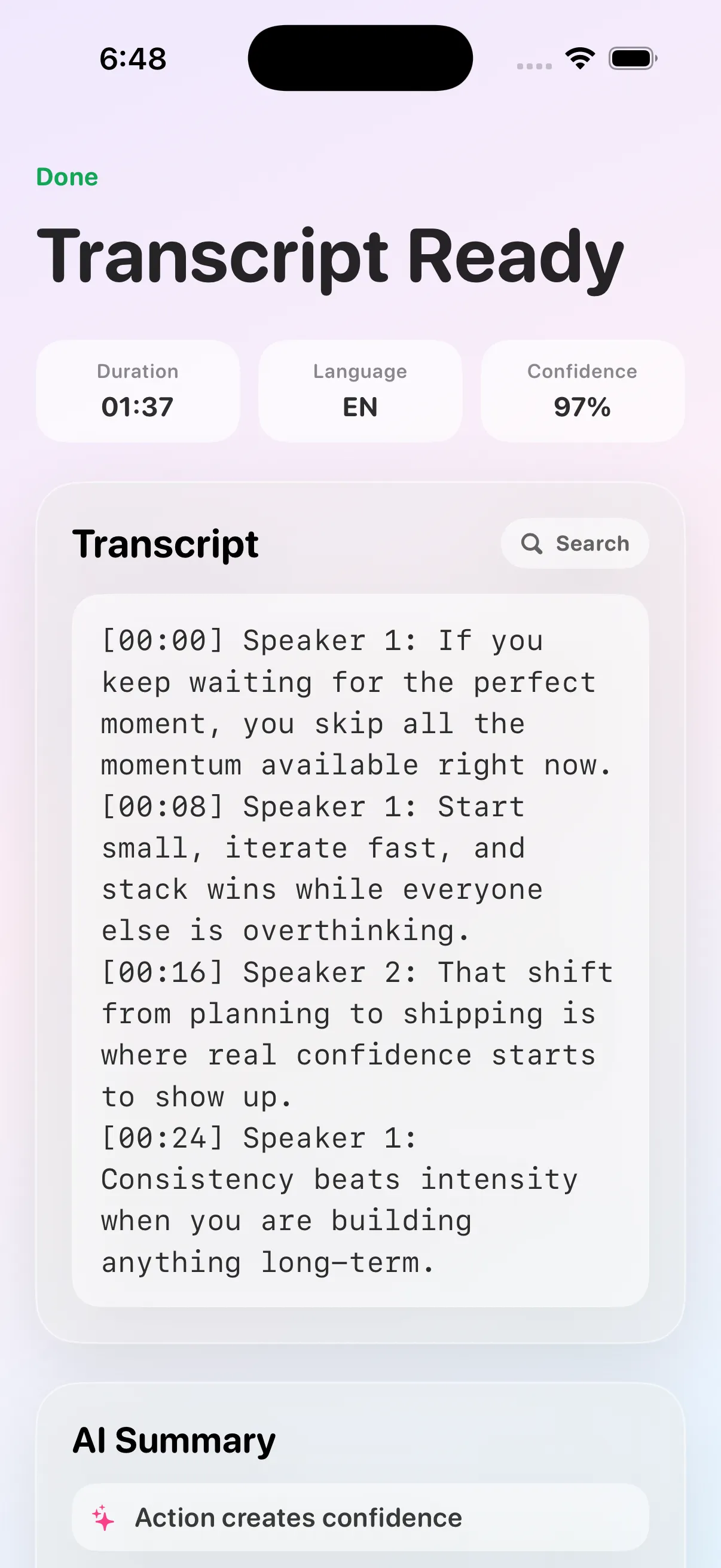
Under the hood, it is engineered for more than demo traffic. The system is designed to process multiple jobs predictably, maintain clarity during long-running operations, and return transcripts in a format that can be reused in content workflows, research, support operations, and social media teams.
What this case study proves
Transcribing App shows how FCT Technologies approaches AI product delivery when the user experience depends on a long-running backend job. Instead of hiding the system complexity behind vague marketing language, the architecture is built around three visible requirements: fast submission, clear progress states, and reliable transcript delivery once the job finishes.
That matters because transcription products fail in predictable ways when the backend is treated like a synchronous request-response flow. Queueing, stage isolation, and deterministic status transitions make the experience feel calmer for the user while keeping the implementation easier to debug and extend later.
Who this product is a fit for
This kind of system is a strong fit for teams handling media-heavy workflows, creator tools, content operations, support documentation, or internal knowledge capture. The product direction also makes sense for businesses that need a reusable ingestion-and-processing pipeline they can later expand into summarization, search, tagging, or downstream AI workflows.
Architecture
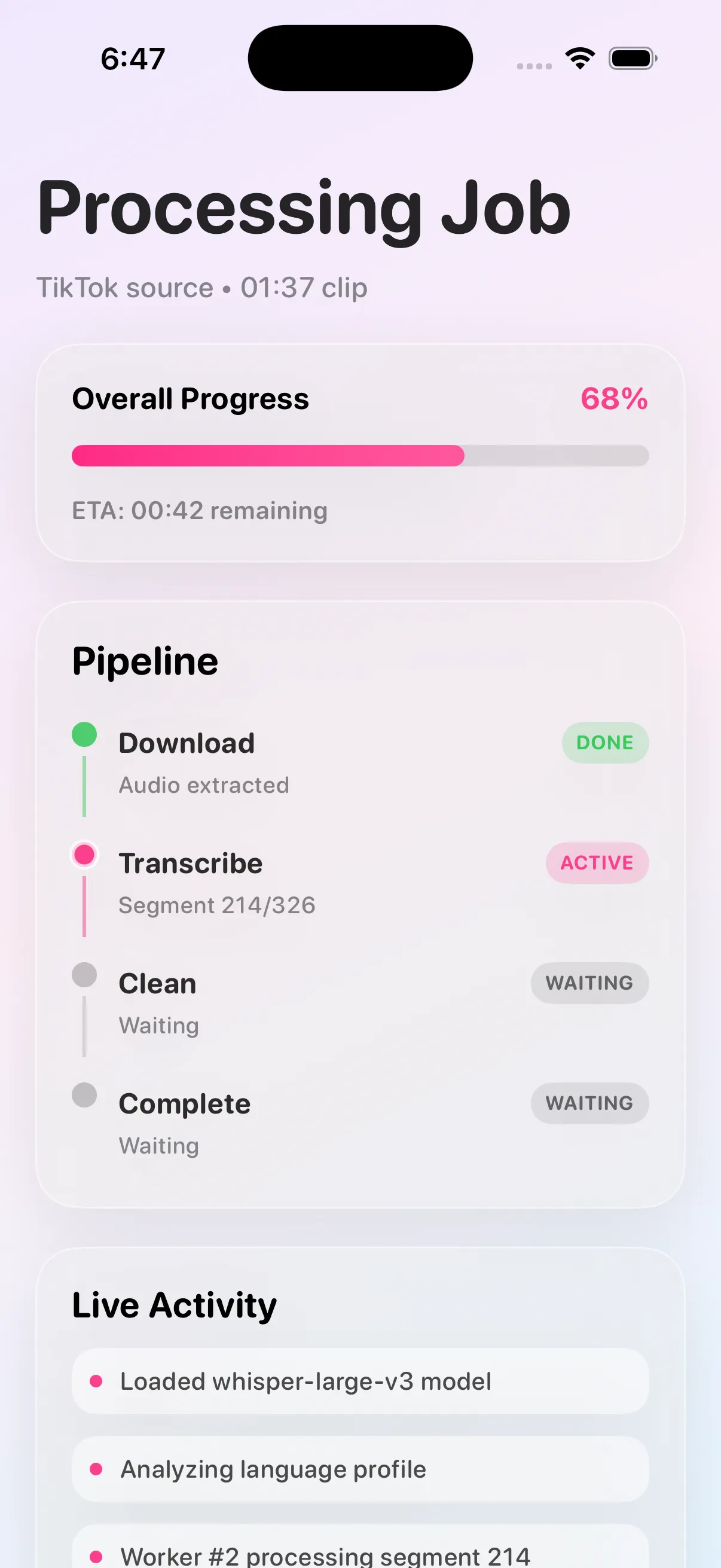
The core architecture is queue-first and service-oriented. Request handling and compute-heavy transcription do not share the same execution path. This keeps the API responsive while workers handle expensive model inference and media processing in the background.
Key architectural traits:
- Strong stage boundaries between ingestion, transcription, and post-processing.
- Explicit state transitions to keep frontends and API consumers synchronized.
- Failure isolation so a bad media job does not degrade the entire system.
- Contract-driven endpoints that support extension into mobile clients and third-party automations.
UX and Product Direction
The UX is intentionally minimal, but structurally backed by robust status semantics. Users are always shown where their request stands, which improves trust and reduces drop-off on longer jobs.
From a product perspective, this enables expansion into:
- team workspaces,
- richer transcript exports,
- collaborative editing,
- and downstream AI summarization/search workflows.
Why the implementation matters commercially
For a business evaluating custom AI software, the main signal here is not just that transcription works. It is that the product is structured so usage can grow without turning operations into guesswork. Users get transparent job progress, the API stays responsive under load, and the platform can support new client surfaces without rewriting the entire system.
Operational Notes
Operationally, the project emphasizes reliability and controllable cost:
- Temporary artifact cleanup prevents unbounded disk growth.
- Retry-friendly status transitions improve recovery from transient media/provider failures.
- Pipeline modularity allows swapping or upgrading model components without rewriting the API layer.
- Worker-oriented execution patterns support horizontal scaling as throughput increases.
The result is a platform foundation that is both user-friendly on the surface and deeply production-aware under the hood.